

Il existe 3 types de contrôle d’admission pour HA : Host Failures Cluster Tolerates, Percentage of Cluster Resources Reserved as failover spare capacity et Specify Failover Host.
L’article suivant essaye d’expliquer d’une manière simple ce que font chacun de ces types de contrôle d’admission HA.
Host Failures Cluster Tolerates : Ce type de contrôle d’admission prévoit “le pire des cas”. C’est à dire que lorsqu’un ESXi crash, il va prévoir le pire des scénarios possibles pour le redémarrage des VMs. Pour cela, il se base sur des slots. Un slot comprend la mémoire et le cpu. Pour composer la valeur du slot d’un cluster, il va prendre la plus grande réservation de mémoire qu’il va trouver dans les VMs du cluster + la mémoire overhead de cette VM. S’il n’y a pas de réservation, il prend 0Go + overhead pour la mémoire. Par exemple, si vous avez une VM de 32Go de mémoire avec une réservation de 16Go, la taille mémoire du slot sera d’environ 16Go (mémoire réservée + overhead).
Pour le CPU, il va prendre la plus grande réservation de CPU qu’il va trouver dans les VMs du cluster ou, s’il n’y a pas de réservation, une valeur par défaut (32Mhz ou 256Mhz). Si vous avez une VM avec 2Ghz de réservation, la taille de CPU du slot sera de 2Ghz.
Une fois le slot composé, le contrôle d’admission HA va regarder la totalité des ressources et va calculer le nombre de slot mémoire qu’il y a en divisant la totalité de la mémoire par la taille du slot mémoire. Il fera la même chose pour le CPU et ce pour chaque ESXi.
Prenons un exemple concret :
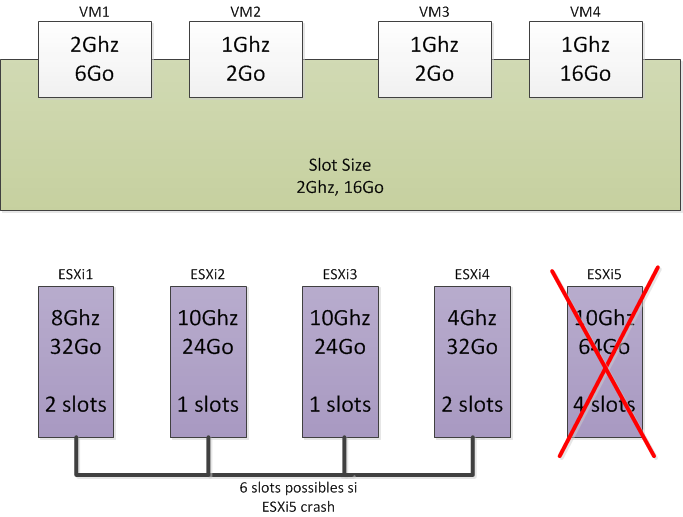
Vous avez 5 ESXi. Vous avez sélectionnez 1 Host Failure Cluster Tolerates, ce qui signifie que la perte d’un hôte est tolérée. Sur votre cluster, la plus grosse VM fait 16Go de réservation mémoire, et la plus grosse réservation CPU fait 2Ghz.
Votre slot fait donc 16Go de mémoire et 2Ghz de CPU.
Selon le principe du Host Failure Cluster Tolerates, vous pouvez donc avoir sur l’ESXi1 32/16 = 2 VMs de 16Go et 8/2 = 4 VMs de 2Ghz. Donc si on se base sur ces calculs, vous pourrez donc avoir que 2 slots sur l’ESXi1. (Valeur la plus basse entre cpu et mémoire). Faire la même chose pour chaque ESXi. Vous pouvez donc avoir 10 slots sur l’ensemble de vos ESXi. Seulement, vous avez sélectionné 1 Host Failure Cluster Tolerates, ce qui signifie que la perte d’un hôte est tolérée. Donc en réalité il n’y a pas 10 slots tolérés mais moins selon l’ESXi qui crash. Sur le schéma, si l’ESXi5 crash, vous perdez 4 slots. Vous pourrez donc avoir 6 slots répartis sur les autres ESXi. En d’autres termes, si l’ESXi5 crash, vCenter redémarrera 6 VMs de cette ESXi sur les autres ESXi avant de considérer qu’il n’y a plus de ressource disponible sur le cluster.
On voit bien ici qu’il suffit d’une VM avec une très grosse réservation (mémoire ou cpu) dans le cluster pour que cette méthode perde de son intérêt. Cependant, il est possible d’utiliser les options das.slotCpuInMHz ou das.slotMemInMB. Le das.slotCpuInMHz permet de fixer une valeur de slot pour le CPU et das.slotMemInMB une valeur de slot pour la mémoire. Si vous avez, comme dans notre exemple, une VM avec une très grosse réservation mémoire (16Go), vous pouvez spécifier das.slotMemInMB à 8Go pour éviter d’avoir une taille de slot trop grande. Le meilleur moyen d’éviter cela, est d’éviter dans la majorité des cas des réservations trop grandes sur les VMs.
A noter que depuis la version 5.1 et la web client, il est possible de configurer les valeurs du slot size directement dans les options. (beaucoup plus intéressant)

Percentage of Cluster Resources Reserved as failover spare capacity : Ce type de contrôle d’admission se base tout d’abord sur la totalité des ressources du cluster. Si on prend notre schéma ci-dessous, on a 24 Go de mémoire et 9Ghz de CPU sur l’ensemble du cluster :

Puis, il va calculer l’occupation actuelle de la mémoire et du CPU en se basant sur les réservations. Pour les VMs sans réservation, par défaut pour chaque VM, HA prend 32 Mhz pour le CPU et 0Go + overhead pour la mémoire.
Dans notre exemple, avec des réservations sur les VMs, l’occupation est de (6+4+4+2)=16Go et (2+1+1+1)=5Ghz.
Le taux de ressources libre se calcul avec la formule suivante : ((taux de ressources globales-taux d’occupation actuelle)/taux ressources globales)*100
Dans notre exemple :
– Taux mémoire libre =((24-16)/24)*100= 33.3%
– Taux cpu libre = ((9-5)/9)*100= 44.4%
Si vous choisissez 25% de CPU et 25% de mémoire comme valeur de pourcentage réservée pour le cluster de ressources, alors HA va faire en sorte que la consommation totale des VMs n’excède pas 75% des ressources globales et réserver ainsi 25% des ressources globales en cas de perte d’un ESXi.
Dans notre exemple, ça revient à ne pas dépasser 75% de 24 Go pour la mémoire donc 18Go et 75% de 9Ghz pour le CPU donc 6.75Ghz pour le CPU.
Dans notre exemple, vous pouvez donc encore rajouter une VMs avec 2Go de réservation ou une VM avec 1.75Ghz de réservé, mais au delà, HA fera en sorte qu’aucune VM ne puisse démarrer.
Specify a Failover Host : Ce type de contrôle d’admission permet de réserver (mettre en stand-by) un ou plusieurs ESXi pour HA. C’est à dire que les ESXi désignés pour HA ne seront pas éligibles pour recevoir des VMs du cluster en fonctionnement normal, même en cas de consommation excessives sur certains ESXi du cluster. Ce ou ces ESXi permettront juste de redémarrer des VMs en cas de crash d’un ou plusieurs hôtes du cluster.
Vous n’avez en aucun cas la certitude que toutes les VMs impactées redémarreront sur le ou les ESXi désignés.

Leave A Comment