
Understanding AI in Infrastructure Automation Envision a horizon where your IT infrastructure predicts issues before they arise, serves itself and scales up or down without any manual intervention — that’s the promise of AIOps. No, this isn’t a sci-fi movie, this the real-world reality of AI powered infrastructure automation and Nutanix Continue Reading
Hybrid cloud made easy with Nutanix NC2
Are you tired of juggling multiple cloud environments, struggling to maintain consistency, and battling complex infrastructure? You’re not alone. In today’s digital landscape, businesses are increasingly turning to hybrid cloud solutions – but implementation can be a daunting task. Enter Nutanix NC2, the game-changing solution that’s revolutionizing hybrid cloud deployment. Continue Reading
360 view on Nutanix NUS (unified Storage)

360 view on Nutanix NUS (unified Storage) Are you tired of juggling multiple storage solutions for your enterprise data needs? ♂️ Enter Nutanix Unified Storage (NUS) – a game-changing solution that’s revolutionizing the way businesses manage their data infrastructure. But what exactly is NUS, and why should you Continue Reading
360 view on Nutanix NKP
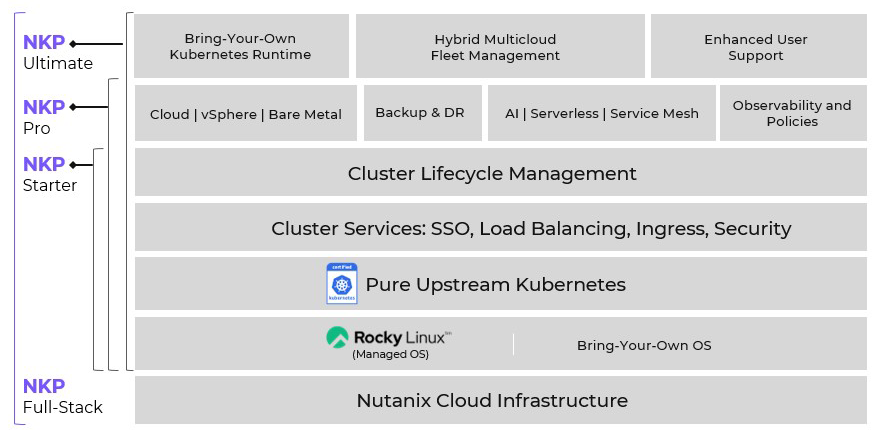
Are you tired of juggling multiple cloud platforms and struggling to manage your Kubernetes deployments? Enter Nutanix Karbon Platform (NKP) – the game-changing solution that’s revolutionizing the way businesses handle their containerized applications. In today’s fast-paced digital landscape, efficiency and scalability are paramount. NKP addresses these challenges Continue Reading
How NUTANIX help you remove the COMPLEXITY from your IT infrastructures
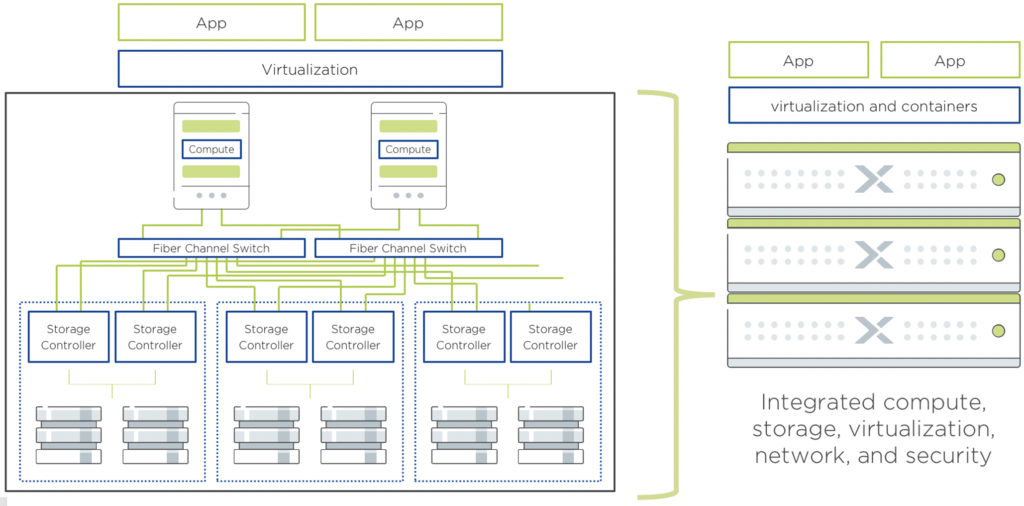
To start this article, I found this Wikipedia definition relevant Complexity characterizes the behavior of a system or model whose components interact in multiple ways and follow local rules; meaning that there is no reasonable higher instruction to define the various possible interactions. The term is generally used to characterize something with many Continue Reading
(Eng) My NPX / VCDX journey and my 2 cents advices

This post follow a previous one where I give a big thank to the vCommunity : Thank you for my NPX / VCDX numbers Fouad EL AKKAD, NPX-18, and VCDX-283 For Reminder What are those Certifications ? They are the highest level on VMware and Nutanix certification program, Continue Reading
Thank you for my NPX / VCDX numbers

I have been thinking about this post from the early beginnings of my NPX / VCDX journey, the whole journey took a bit more time than I had planned for but finally, it’s time. It’s time to be thankful, recognize all the great help that I received during my Continue Reading
VMware : State mémoire de l’ESXi (High, Clear, Soft, Hard & Low)
Suite à notre article sur l’exploitation de TPS et pour compléter notre Deep Dive sur la gestion mémoire de l’ESXi. On va se tourner sur l’exploration des “states” ESXi sous vSphere 6, car en v5 les seuils ne sont pas les mêmes Prérequis de lecture Continue Reading
VMware : Mécanisme mémoire ESXi
Nous dépoussiérons un sujet largement abordé mais malheureusement manquants à notre blog mais aussi pour compléter notre Deep Dive sur la gestion RAM ESXi On va donc essayer de vous faire un condensé d’informations sur les mécanismes d’optimisations de RAM. Les mécanismes de récupérations de RAM s’exécutent séquentiellement, selon Continue Reading
VMware : ESXi – Large Page OR NOT Large Page – Telle est la question ?
Prérequis à cette article : VMware : Mécanisme mémoire ESXi TPS or Not, Salt, Salting, Exploit AES, ESXi 5.5 u2, ESXi 6, …… Mise au clair Explication TPS est arrivé aux jours, ou les VMs avaient des OS principalement 32 bits avec des pages mémoires à 4kb (Rappel Continue Reading
Nutanix Foundation : Installation de noeuds
Nutanix Foundation est un utilitaire/service permettant de réaliser une installation complète de nœuds Nutanix Cet utilitaire est disponible pour les employés Nutanix et partenaires principalement. On distingue 2 Foundations : Foundation (in CVM on va dire), aussi appelé CVMF qui est un service porté par les CVM afin de réaliser Continue Reading